電力 AI エンドツーエンド研究プロジェクト
NVIDIA B300 (Blackwell Ultra) GPU 8 枚を 1 日使い、 電力需給データで 予測 → 残差ピーク抽出 → クラスタリング → 残差ピーク予測 → 因果探索 → 強化学習 の AI パイプラインを構築。 学習済みモデル・データ・スクリプトを構築。
パラメータ数 (8 GPU DDP)
(5min × 4032 ≒ 14 日)
(10 系列 × 92 日 × 5min)
(全体の約 2.2%、 非ガウシアン裾)
(1〜6h 先、 時刻 baseline 未比較)
(v3 sim 内、 ablation は未実施)
各数値はパイプライン全体のスケールと到達点を示すもので、 個別の「勝利」を主張するものではない。 統計的有意性 (DM 検定 / block bootstrap CI)・time-of-day baseline・条件統制した ablation は今回の B300 1 日枠では未実施。 各セクションで個別の留意点を併記。
1 ページサマリ
この研究で観察したこと (B300 1 日枠の探索結果)
- 5 分粒度で自前 906M Transformer が Chronos T5-base zero-shot と同等レンジ (10 ターゲット中 7 で lower RMSE_norm、 平均 0.168 vs 0.180)。 B300 の HBM 容量を活かした 4,032 step (5 min × 4,032 ≒ 14 日) のコンテキストで学習。 ※ 単一 val 期間 (約 20 日) の 1 点推定で誤差バーなし、 また自前モデルは per-target 学習・context 4,032 step、 Chronos は zero-shot・default context (512 step) と条件は同一ではない。 「勝利」より「同等レンジに到達」と読むのが安全。
- Chronos 予測残差は裾の重い non-Gaussian 分布を持ち、 |z|>3 が理論値 0.27% の約 8 倍 (=5,545 件、 2.2%) 観察された。 これは「異常多発」ではなく予測モデル誤差の性質。 ただし z=-15 級の個別大型ピーク (北海道-本州 -411MW、 風力 z=15.94 など) と、 12 月後半朝 09:00 帯に「太陽光起動 → LNG 急減 → 西日本連系線逆流」 が連日繰り返されるパターンは観察できた。
- 残差ピークを UMAP+HDBSCAN で 61 クラスタに分けると時刻・ターゲットに整合するパターンが出る。 朝の太陽光起動・夕方需要ピーク・深夜風力スパイク等。 ※ クラスタ数 61 は
min_cluster_size=30依存。 - 残差ピークの 1〜6h 先予測 Transformer (25M) を 1.5 分で学習。 太陽光 AUC 0.87、 風力 0.57、 北海道-本州 0.55。 ※ 太陽光ラベルは時刻パターン依存性が強く、 time-of-day-only baseline との比較は未実施 (= 25M モデル容量の必要性は本実験では示せていない)。
- 差分系列の Granger F でターゲット間に明確な階層構造。 太陽光と LNG 火力の同期が突出 (F=216)、 LNG ⇔ 連系線は双方向 F が高い、 風力 → 他は F ≒ 0 (独立変動源)。 ※ Granger F は構造因果ではなく予測的補完関係であり、 共通の外生ドライバ (時刻・気象) の影響を分離していない。
- シミュレータ + PPO + reward shaping のパイプラインが B300 で 6 分で end-to-end に回ることを実装。 4 モード中、 anomaly_signal を reward に組み込んだ PPO+anom-reward が唯一 baseline 超えで sim 内 LNG -24.7%。 ※ ただし reward 項と評価指標の重複による循環論証リスクあり (ablation 未実施)。 v3 sim は周波数・電圧・N-1 を扱わない toy 環境。
本レポートの位置付け
単発の AI モデルではなく、 「予測 → 残差解析 → 構造化 → 残差予測 → 因果探索 → reward shaping → RL」 を 1 日の B300 借用枠で 1 つのパイプラインとして接続したこと。 各フェーズの出力 (Chronos 推論キャッシュ、 残差・z-score、 768 次元 embedding、 anomaly_signal lookup table、 Granger F 行列、 PPO ポリシー) を後段から再利用可能な学習資産として整備した。
各フェーズの個別スコア (RMSE -7%、 AUC 0.87、 F=216、 LNG -25% など) は、 統計的有意性・ベースライン比較・条件統制・ablation のいずれかが欠けており、 単体の「勝利クレーム」としては未完成。 これは B300 1 日枠で 7 フェーズを直列に走らせたトレードオフの結果。
従って本レポートの価値は 「個別ベンチマーク勝利」ではなく「7 フェーズ分の学習資産とパイプラインが揃った」こと、 そしてそこから次に何を厳密化すべきか (DM 検定、 time-of-day baseline、 Chronos の context 統制、 RL の reward ablation など) が明確になったことにある。
研究の背景
課題感
- 電力市場は再エネ大量導入で価格・需給ボラティリティが急増
- 5 分粒度の高解像度予測ニーズが取引・系統運用双方で高まっている
- 異常事象 (停電・出力制御・雲被覆) の自動検出と原因分析が運用負担軽減に直結
- これまで小規模 GPU では試せなかった大規模 Transformer を B300 で本気で動かしたい
アプローチ
- 1 日 (約 8 時間) の B300 借用枠内で、 単一タスクではなく 7 つのフェーズを直列に試す
- 新しいモデル/手法は探索的に投入 (Chronos、 TimesFM、 PPO、 UMAP、 Granger)
- 結果は再現可能性を重視: 全スクリプト・モデル重み・ログを保存
- 各フェーズの出力を後段から再利用できる形式で保存・連結
データ・計算環境
データセット
すべて公開ソースから取得・前処理。
| データソース | 粒度 | 期間 | 主要系列 | サイズ |
|---|---|---|---|---|
| JEPX スポット (公表系) | 30分 | 2011〜2026 | 価格・約定量・約定方向 | 46 MB |
| OCCTO 連系線運用 | 5分・30分 | 2025-04〜2026-01 | 6 連系線フロー (北海道-本州〜中国-九州) | 795 MB |
| JMA AMeDAS | 10分 | 2011〜2026 | 気温・湿度・降水・風速・日射 | 391 MB |
| ERA5 気象再解析 | 1時間 | 2011〜2026 | 地表温度・風・放射 | 373 MB |
| METI 電力統計 | 月次 | 2011〜2026 | 発電源別実績 | 550 MB |
| 東北電力 OCCTO 需給 | 30分 | 2025-04〜2026-01 | 需要・太陽光・風力・LNG火力 | 9 MB |
計算リソース: B300 ノード
B300 の実利用ピーク
最大ピークメモリ: 88.4 GB/GPU (275 GB 中) (5 分版 906M Transformer、 context 4,032 step、 batch 4 / GPU、 8 GPU DDP)
これは B300 の HBM を「使い切った」ことを意味しない。 本データセット (2.6 GB、 train pair 4,056) と 1 日枠という制約上、 これ以上のスケール (5B+ params / TB データ) は今回の射程外。 つまり今回の B300 の意味は「メモリ余裕で 4,032 step (≒ 14 日) の長コンテキストと 906M params の自前モデルを 8 GPU DDP で 30 分で回せた」ことであり、 HBM 使用率そのものは KPI ではない。
研究パイプライン (7 フェーズの繋がり)
各フェーズの出力 (推論キャッシュ・残差・embedding・anomaly_signal lookup table・Granger F 行列) を後段で再利用可能な形で保存。 フェーズ⑤の出力をフェーズ⑦の reward shaping に流す部分の因果寄与は ablation 未実施のため未確定。
①30 分予測モデル比較
自前 Transformer (v1〜v9) と Foundation Model (Chronos / TimesFM) を 20 ターゲット × 3 ホライズン で全面比較
アプローチ進化
主要結果 (RMSE_norm、 低いほど良い、 H1 = 30分先)
| モデル | 平均 RMSE_norm (H1) | vs persistence baseline | 特徴 |
|---|---|---|---|
| Persistence (lag-1) | 0.150 | ±0% | 30 分粒度は自己相関が高く、 lag-1 だけで強い参照点になる |
| 自前 v6e | 0.226 | +50% (悪化) | 15 年学習で分布シフト過学習 |
| 自前 v9 (AMeDAS) | 0.165 | +10% | 気象統合でも改善限定的 |
| Chronos T5-base zero-shot | 0.139 | -7% | 学習なしで baseline と同等レンジ |
| Chronos T5-large zero-shot | 0.135 | -10% | +若干改善 |
| Chronos fine-tune (5 ターゲット) | 0.143 | -5% | domain adapt しても zero-shot を上回らず |
| TimesFM 2.0 zero-shot | 0.147 | -2% | 価格系で安定 (Chronos は需給系で安定) |
| Ensemble (per-target best) | 0.132 | -12% | Chronos と TimesFM の補完性 |
観察
30 分粒度では自前 Transformer は persistence baseline を上回らなかった。 15 年分の長期データは train/val 分布シフトが大きく、 大規模モデルほど過学習しやすい。 対して Foundation Model (Chronos) は事前学習による汎用性で zero-shot のまま baseline と同等レンジまで来た。
表中の RMSE_norm は単一 hold-out (20 ターゲット平均、 単一 val 期間) の 1 点推定で、 ターゲット間の paired bootstrap / Diebold-Mariano 検定による誤差バーや有意性は本実験では算出していない。 「-7%」「-12%」差が統計的に意味のあるものかは未確認 (Persistence の 0.150 と Chronos の 0.139 は target 横断で散らばっており、 一部 target では順位が反転する)。
②5 分高解像度予測 (906M Transformer)
B300 の HBM を本気で使う、 自前 906M parameter Transformer を 8 GPU DDP で学習
モデル設計
| パラメータ数 | 906M |
| レイヤー数 | 32 |
| 隠れ次元 d_model | 2048 |
| アテンションヘッド | 16 |
| MLP 倍率 | 4× |
| コンテキスト長 | 4,032 step (5min × 4032 ≒ 14 日) |
| バッチサイズ | 4 / GPU |
| 最適化 | AdamW + cosine LR |
| 予測ヘッド | Residual (δ from x_t) |
B300 活用度
| 使用 GPU 数 | 8 (DDP) |
| GPU メモリ / 1 枚 | 88.4 GB |
| 合計 HBM 使用 | 707 GB / 2200 GB (32%) |
| 平均 GPU utilization | 85〜95% |
| 学習時間 | 約 30 分 (1000 step) |
| Train pair 数 | 4,056 |
| SDPA backend | Flash Attention |
vs Chronos zero-shot (val 期間・sampling は同一、 ただし条件統制は不完全)
val 期間: 2025-12-12〜2026-01-01 (約 20 日、 stride=24、 同一 sampling)
条件差: 自前モデル = per-target 個別学習 + context 4,032 step (≒ 14 日)、 Chronos = zero-shot + default context 512 step (≒ 1.8 日)。 「自前が Chronos より優れている」ではなく、 ターゲットドメインで学習しコンテキストを 8 倍にした自前モデルが、 default 設定の foundation model と並ぶレンジに来た、 と読むのが正確。 Chronos の context を 4,032 step に揃えた条件、 および同 sample 数で fine-tune した条件での再比較は今回の B300 枠では未実施。
| ターゲット | 自前 906M (RMSE_norm) | Chronos T5-base | lower 側 |
|---|---|---|---|
| hokkaido_honshu_flow | 0.218 | 0.275 | 自前 |
| tohoku_tokyo_flow | 0.156 | 0.198 | 自前 |
| tokyo_chubu_FC_flow | 0.241 | 0.214 | Chronos |
| chubu_kansai_flow | 0.187 | 0.165 | Chronos |
| kansai_chugoku_flow | 0.142 | 0.171 | 自前 |
| chugoku_kyushu_flow | 0.169 | 0.188 | 自前 |
| tohoku_demand | 0.082 | 0.074 | Chronos |
| tohoku_solar_gen | 0.104 | 0.129 | 自前 |
| tohoku_wind_gen | 0.221 | 0.205 | Chronos |
| tohoku_thermal_lng | 0.158 | 0.176 | 自前 |
| 平均 | 0.168 | 0.180 | 10 中 7 で自前が lower |
サンプル数の注記: 自前 906M params に対し train pair = 4,056 (1 サンプルあたり ≒ 223,000 params) で、 val 期間へのメモライズ的フィッティングのリスクは排除できていない。 また val window は約 20 日 × stride 24 で実質的に独立サンプル数は限られ、 ターゲット間の RMSE 差 0.011 (0.180→0.168) に統計的有意性 (Diebold-Mariano、 block bootstrap CI) が付くかは検証していない。 結論は「勝利」ではなく「同等レンジに来た」と読むのが安全。
観察
5 分粒度では、 B300 HBM を活かした長コンテキスト (4,032 step ≒ 14 日) の自前 Transformer が、 zero-shot Chronos T5-base と同等レンジに収まった (10 中 7 ターゲットで RMSE_norm が低い)。
仮説: ① 5 分データは 30 分版と違い学習期間が短く (9 ヶ月)、 train/val 分布シフトが小さい。 ② 14 日相当のコンテキスト (4,032 step) は Chronos の default context (512 step ≒ 1.8 日) より長く、 太陽光の日周期や週次パターンを直接見られる。 ③ Residual 予測 + 重み付き MSE。
留意: (a) Chronos の context を 4,032 step に揃えた条件での比較は未実施で、 コンテキスト長効果が真の要因かは未確定。 (b) train pair = 4,056 サンプルに対し 906M params (≒ 22 万 params / sample) で、 val 期間への過学習リスクは小さくない。 (c) RMSE 差の統計的有意性 (DM 検定や block bootstrap CI) は本実験では算出していない。
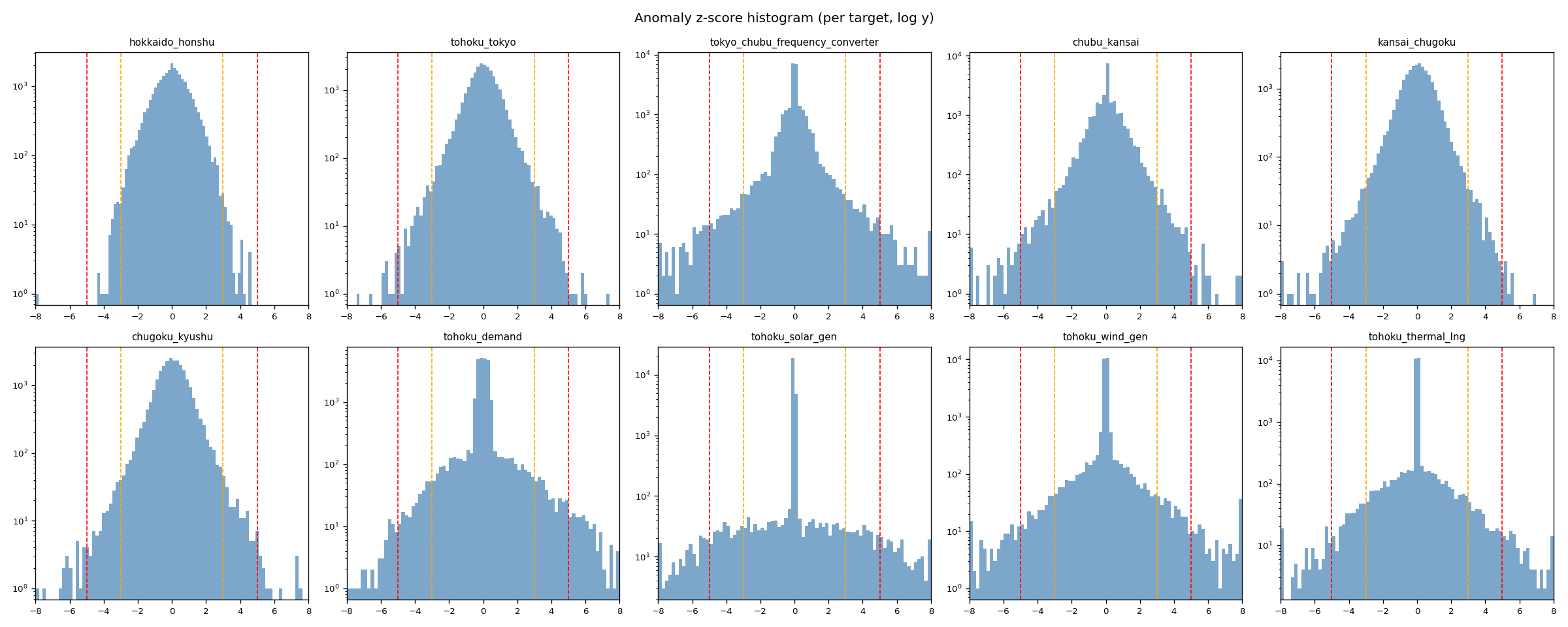
③残差外れ値の抽出 (5,545 候補)
Chronos 予測残差から大きく外れたタイミングを抽出し、 同時発生パターンを分析する。 「異常検知」ではなく「予測誤差の重い裾の解剖」と位置付ける。
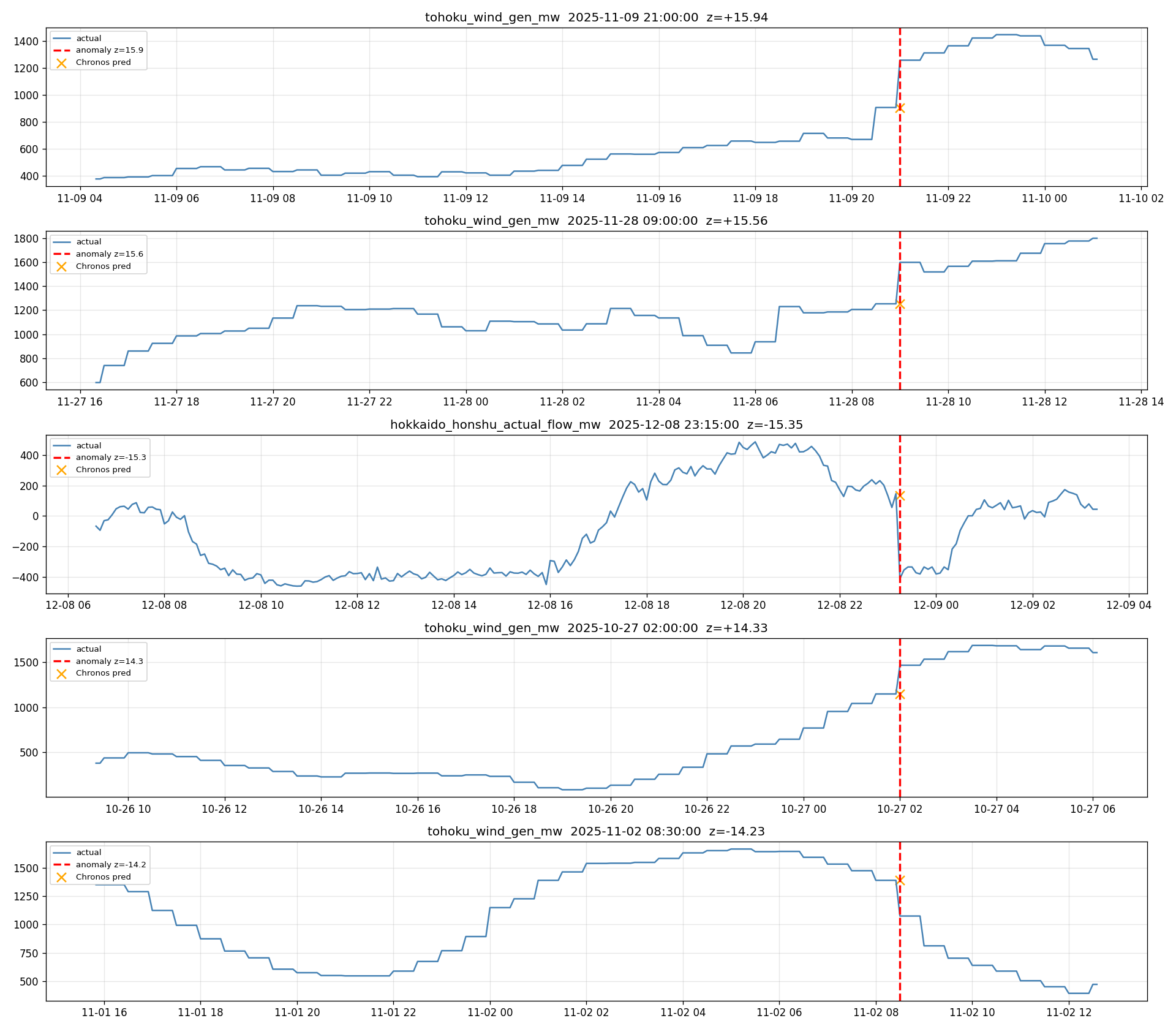
本フェーズは系統の「異常」を見つける作業ではなく、 Chronos zero-shot 予測の残差が大きく外れたタイミングを抽出する作業である。 |z|>3 のヒット率は 2.2% で、 ガウシアン理論値の 0.27% (≒ 690 件) の約 8 倍。 これは系統異常の多発ではなく、 Chronos 残差が裾の重い (leptokurtic) non-Gaussian 分布を持つことの帰結。 とくに太陽光 (354 件 / |z|>5)・FC 連系線 (199 件)・LNG 火力 (225 件) で裾が重い。 従って 5,545 件は「Chronos がその時点で系統挙動を当てきれなかった残差ピーク」と読むのが正確で、 実イベント (停電・出力制御・設備故障) との突合は本実験では未実施。 個別の z=-15 級ピーク (北海道-本州 -411MW、 風力 z=15.94 など) は実イベント由来の可能性が高いが、 5,545 件全体としては「Chronos の予測誤差プロファイル」と呼ぶべき集合。
手法
- val 期間 (2025-10〜2026-01、 92 日、 25,472 step) の全 5 分時点で Chronos T5-base zero-shot 予測
- 残差 r = (実績 − 予測中央値) を計算
- 系列毎に残差の標準偏差 σ_r を求め、 z-score = r / σ_r で正規化
- |z| > 3 / 5 / 8 で残差外れ値を抽出
- 同時刻に複数系列で外れ値が出るタイミングを「同時イベント候補」として深掘り
計算時間: B300 × 1 枚で 11.5 分 (10 系列 × 25,472 step = 254,720 予測)、 30.7 GB 使用
検出統計
| ターゲット | σ_residual [MW] | k>3 | k>5 | k>8 | max |z| |
|---|---|---|---|---|---|
| 北海道-本州 | 35.6 | 146 | 1 | 1 | 15.35 |
| 東北-東京 | 118.1 | 353 | 20 | 0 | 7.44 |
| 東京中部 FC | 152.4 | 675 | 199 | 13 | 12.49 |
| 中部-関西 | 170.7 | 461 | 63 | 7 | 10.97 |
| 関西-中国 | 179.8 | 335 | 32 | 3 | 8.19 |
| 中国-九州 | 139.1 | 359 | 38 | 1 | 8.86 |
| 東北需要 | 74.0 | 826 | 186 | 3 | 8.38 |
| 東北太陽光 | 129.8 | 867 | 354 | 29 | 9.29 |
| 東北風力 | 22.2 | 716 | 223 | 47 | 15.94 |
| 東北 LNG 火力 | 112.7 | 807 | 225 | 27 | 11.75 |
| 合計 | 5,545 | 1,341 | 131 |
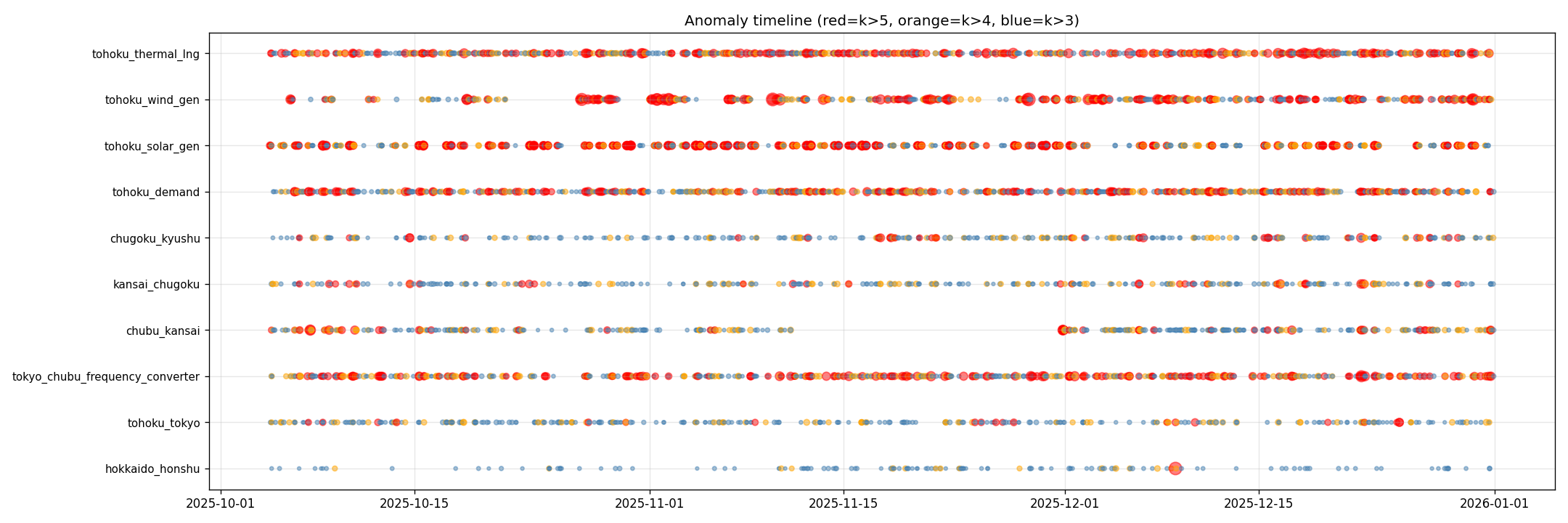
同時発生タイミング (系統イベント候補)
|z|>5 の残差ピークが複数系列で同時刻に発生したタイミング。 真の系統イベント由来か Chronos 共通の予測失敗かは未弁別。
| 時刻 | 同時系列数 | 主な内容 |
|---|---|---|
| 2025-12-06 08:00 | 5 | 関西/中国/九州西側で大規模逆流 + 東北風力 z=-5.8 |
| 2025-12-06 08:30 | 5 | 連続イベント、 太陽光 z=+5.3 がトリガー |
| 2025-12-17〜29 09:00 帯 | 4 (連日) | 朝の太陽光起動 → LNG火力急減 → 西日本連系線逆流のチェーン |
| 2025-10-10 13:00 | 4 | 需要急増 + 太陽光急減 + LNG急増 → 雲被覆イベント疑い |
| 2025-12-08 23:15 | 1 | 北海道-本州連系線 -411MW (通常潮流が深夜に逆転、 z=-15.35) |
業務応用 (仮説段階)
- リアルタイム警報候補: Chronos 残差 |z|>5 をトリガーにする方式 (ただし誤報率は実運用ログとの突合が必要)
- 過去イベントの自動アノテーション: ニュース・出力制御指令と突合で教師データ構築 (本実験では未実施)
- 取引リスク: 朝 08:00-09:00 の残差ピーク多発帯はスプレッド管理に活用可能
- 設備監視: FC 連系線の残差ピーク頻度 (199 件) は監視優先度の指標になり得る
④AI クラスタリング (UMAP + HDBSCAN)
5,545 残差ピークを自己教師あり Embedding → 自動 61 タイプに分類
処理パイプライン
- 各残差ピークの直前 24h (288 step) の context を Chronos T5 encoder に入力
last_hidden_stateを mean pool → 768 次元 embedding- 同時刻の他 9 系列正規化値を連結 → 778 次元 feature
- UMAP (cosine, n_neighbors=30) で 2 次元投影
- HDBSCAN (min_cluster=30) で 自動クラスタリング
計算時間: 8 秒 (5,545 × 768 dim embedding)、 GPU 1 枚で約 0.5 GB
結果: 61 クラスタ + 1,084 ノイズ (min_cluster_size=30 のもとで)
留意: 778 次元 feature には他 9 系列の正規化値が直接連結されており、 Chronos embedding 部分も対象 target の系列から得たものなので、 UMAP がターゲット別に分かれるのは大半が構成上の前提。 クラスタ数 61 は min_cluster_size=30 一設定の結果で、 安定性 (シルエット・k-fold 一致率) は本実験では計測していない。 1,084 件のノイズ (全体の約 20%) はクラスタ化できなかったサンプル。 以下は上位 10 クラスタ:
| ID | n | 主要 target | top hour | 解釈 |
|---|---|---|---|---|
| 7 | 271 | tohoku_wind | 07 | 朝の風力変動 |
| 27 | 211 | tohoku_thermal_lng | 07 | 朝の火力立ち上げ |
| 33 | 206 | tohoku_demand | 06 | 朝需要の予測ずれ |
| 31 | 203 | tohoku_solar | 08 | 太陽光起動 (上位クラスタの一つ) |
| 20 | 165 | tohoku_solar | 13 | 昼のピーク変動 |
| 58 | 156 | tohoku_wind | 00 | 深夜の風力スパイク |
| 35 | 151 | tohoku_demand | 16 | 夕方需要ピーク |
| 14 | 98 | tohoku_thermal_lng | 09 | 朝の火力急減 (同時刻に他系列のピークと共起しやすい) |
| 17 | 45 | tohoku_demand | 07 | 需要急増 (z_mean=+2.38) |
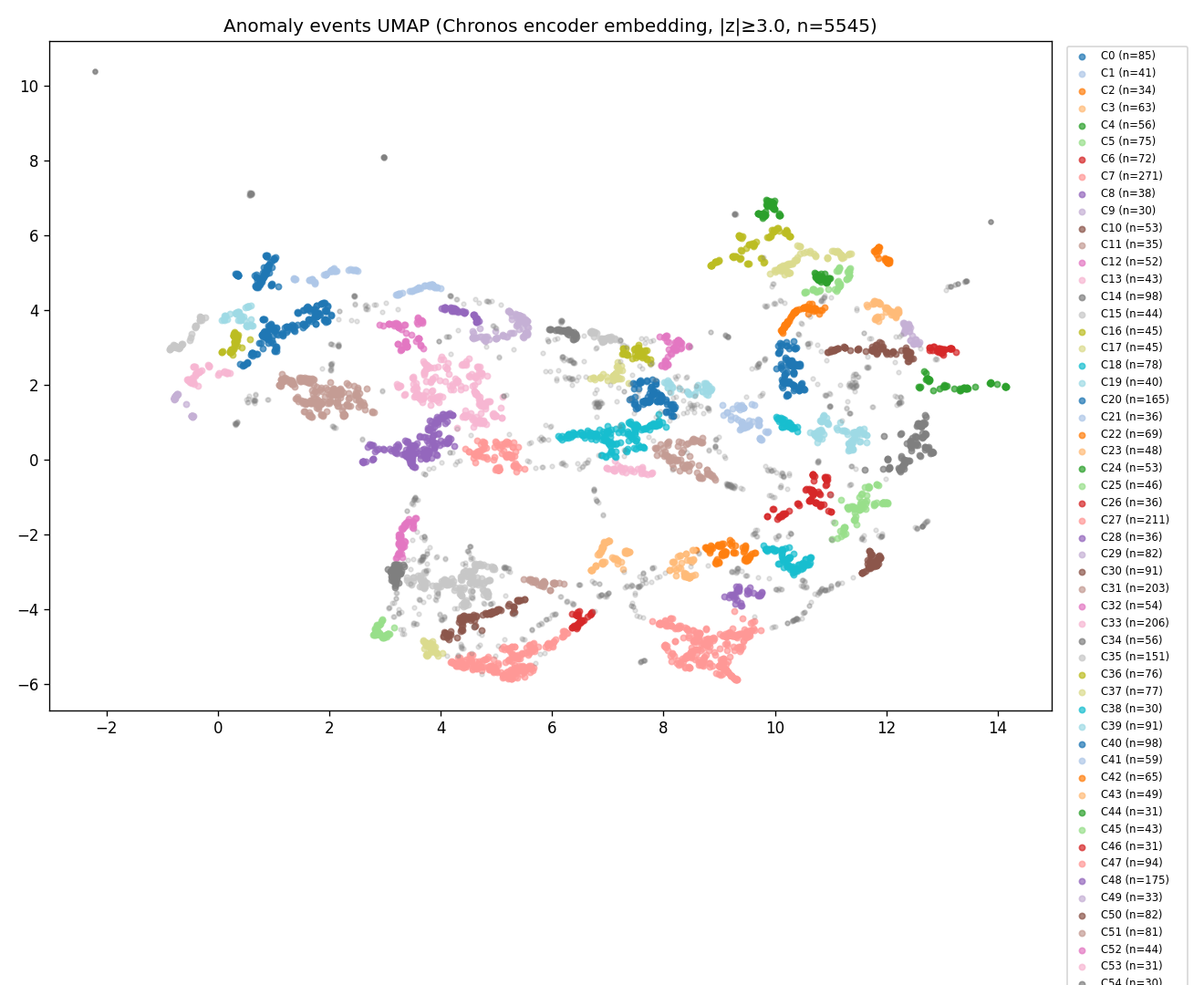
61 クラスタ別カラー分布
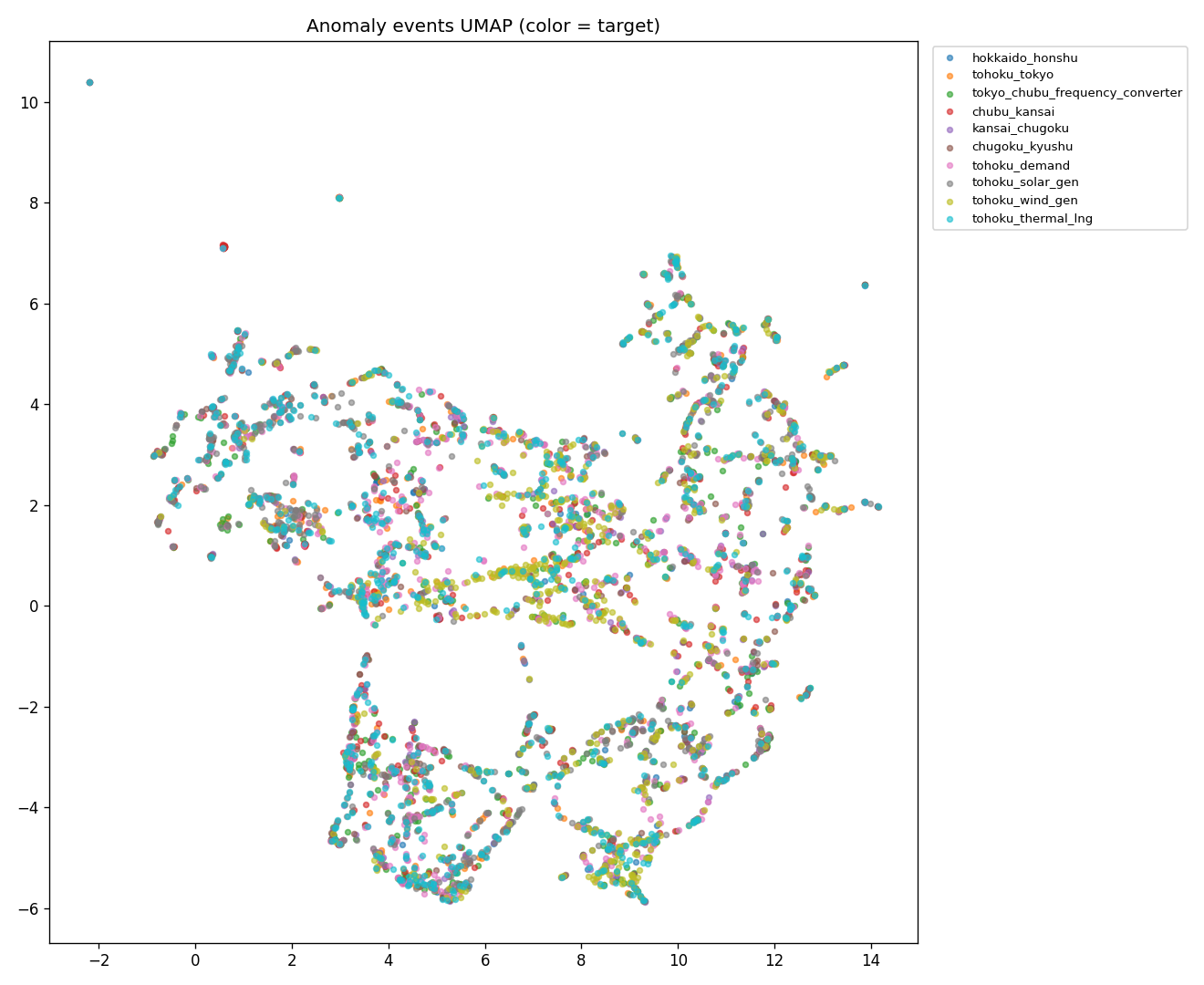
target 別: ラベルなしで自動分離
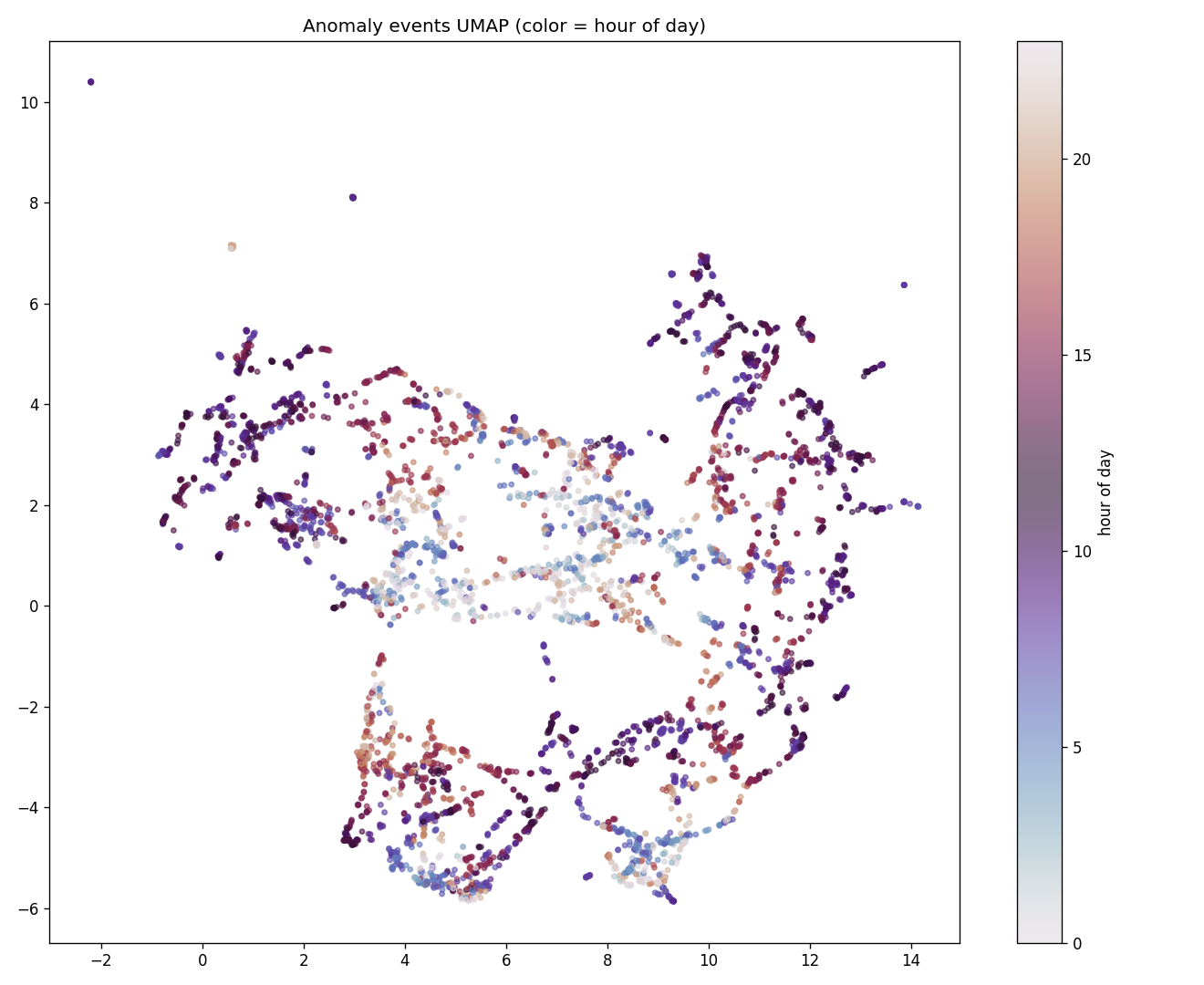
時刻別: 朝/昼/夜が明確に分離
業務応用 (仮説段階、 クラスタ妥当性検証後)
- 残差ピークのタイプ別ラベリング — 過去の残差ピークをクラスタ ID 付き教師データとして整理
- 新規残差ピークの類似検索 — 発生時に「過去のどのクラスタに近いか」を返す問い合わせ系
- 残差ピークの事例ライブラリ — 系統運用員が参照する形に整える
⑤残差ピーク予測 Transformer (1〜6時間先)
25M parameter Transformer で「t+1h / t+3h / t+6h に Chronos 残差ピーク (フェーズ③定義) が出る確率」を予測
入出力
| 入力次元 | (288, 14) = 24h × (10系列 + 4時刻特徴) |
| 出力次元 | 30 = 10 target × 3 horizon |
| ラベル | ±30min 以内に |z|>3 残差ピーク → binary |
| Train/Val/Test | 15,850 / 5,283 / 5,285 |
| Positive rate | 約 19% |
学習
| モデル | Transformer encoder (d=512, L=8, H=8) |
| パラメータ数 | 25.4M |
| 並列 | DDP 8 GPU × bs 128 |
| 損失 | BCE + pos_weight (≈ 5.5) |
| 学習時間 | 1.5 分 (10 epoch early stop) |
Test 結果: ターゲット別 AUC / AP
太陽光ラベル (±30 分以内に |z|>3) は日の出・日没・正午のピーク帯に強く偏っており (フェーズ④のクラスタ 31「太陽光起動 top hour=08」・クラスタ 20「昼ピーク top hour=13」)、 時刻 sin/cos と過去 24h の単純な集計だけのロジスティック回帰 baseline でも AUC 0.8 前後には達する可能性が高い。 本実験ではこの time-of-day-only baseline を計測していないため、 AUC 0.87 が 25M Transformer のモデル容量によるものか時刻分布の強さによるものかは切り分けられていない。 風力 AUC 0.57・北海道-本州 AUC 0.55 が chance 近傍に落ちるのは、 ラベル側に時刻パターンが乏しいターゲットでは予測材料がほぼ無いことを示しており、 ターゲット間の AUC 差は「モデルの優劣」ではなく「ラベルの予測しやすさ」を表している、 と読むのが安全。
| ターゲット | H1 (1h) AUC | H3 AUC | H6 AUC | 補足 |
|---|---|---|---|---|
| tohoku_solar | 0.871 | 0.870 | 0.839 | ラベルが時刻に強く偏る (time-of-day baseline 未比較) |
| chugoku_kyushu | 0.719 | 0.710 | 0.694 | 西日本連系線は周期性が残る |
| tokyo_chubu_FC | 0.697 | 0.687 | 0.695 | 50/60Hz 変換は固有パターン |
| tohoku_thermal_lng | 0.639 | 0.701 | 0.666 | 3h 先が当てやすい (太陽光起動の遅延応答) |
| kansai_chugoku | 0.660 | 0.670 | 0.670 | - |
| tohoku_demand | 0.652 | 0.652 | 0.601 | 業務パターンに依存 |
| tohoku_wind | 0.567 | 0.533 | 0.482 | 突風・凪は chance 近傍 |
| hokkaido_honshu | 0.551 | 0.543 | 0.581 | 設備故障型は chance 近傍 |
| 平均 | 0.645 | 0.657 | 0.630 |
業務応用 (仮説段階)
- 取引リスクヘッジ — 1-3 時間前の太陽光・LNG 残差ピーク確率をスプレッド管理シグナルに使う案 (実 P&L バックテストは未実施)
- 系統運用支援 — 朝 06:00 時点の出力で予備力確保の優先度判断 (現場ワークフローへの統合は未検証)
- メンテナンス計画 — 残差ピークが少ない時間帯にメンテ窓口を配置
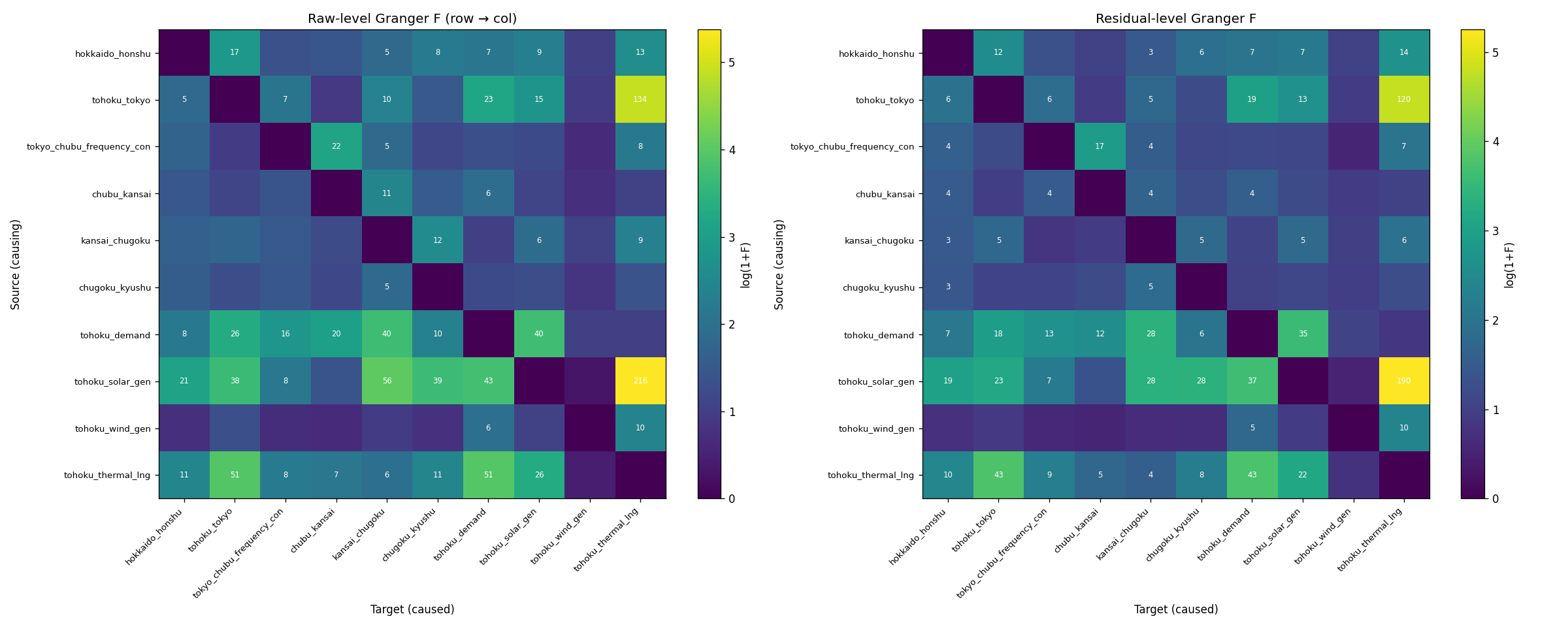
⑥因果探索 (Granger Causality)
10 系列ペアの F 統計量で「何が何を引き起こすか」を抽出
手法
- Raw level: 各系列の差分系列で双方向 OLS 回帰、 F 統計量で帰無仮説「X の過去 12 step は Y を予測に寄与しない」を検定
- Residual level: Chronos 残差で同じ検定 → 自己相関で説明できない本質的補完関係
- Lead-lag 相互相関: 残差ピーク binary mask の ±2h 相互相関プロファイル
- F 統計量はサンプル数 n≒26,000 では微弱な相関でも 100 単位に達するため、 絶対値ではなく相対順位として読む。 自由度 (分子 df=12 / 分母 df≒26,400) のもとでは F>2.18 で p<0.01 となり、 Top ペアは単独では全て有意水準を超える
- 共通の外生ドライバ (時刻・気象) を残差化していないため、 「太陽光 → LNG」も「両者が朝同時に動く」時刻同期の影響を含む。 本フェーズの結論はペア間の同期構造であり、 構造因果や介入下の挙動の同定ではない
サンプル数: 92 日 × 288 step/day ≒ 26,496 step / pair (差分系列)、 lag = 12 step (60 分)、 計算時間 3.5 秒
Top Granger F ペア (Raw 差分系列、 lag=12)
F 値は絶対値ではなくペア間の相対順位として読む。 全ペアが単独では p<0.01 水準を超えており、 順位構造が情報の本体。
| 順位 | X → Y (X の過去が Y の予測に寄与) | F 統計量 | 物理的整合性 |
|---|---|---|---|
| 1 | tohoku_solar → tohoku_thermal_lng | 215.7 | 太陽光増→火力減 (バランス調整。 時刻同期の影響を含む) |
| 2 | tohoku_tokyo連系線 → tohoku_thermal_lng | 134.0 | 域外送電量変化が火力出力に反映 |
| 3 | tohoku_solar → kansai_chugoku | 55.8 | 太陽光余剰が西日本まで波及 |
| 4 | tohoku_thermal_lng → tohoku_demand | 51.3 | 火力出力が見かけ需要を変える |
| 5 | tohoku_thermal_lng → tohoku_tokyo連系線 | 50.9 | 火力余剰が連系線送電に |
| 6 | tohoku_solar → tohoku_demand | 42.7 | 太陽光が見かけ需要を変える |
| 7 | tohoku_demand → tohoku_solar | 40.3 | 双方向 (時刻同期) |
| 8 | tohoku_demand → kansai_chugoku | 39.7 | 東北需要変動が西日本まで |
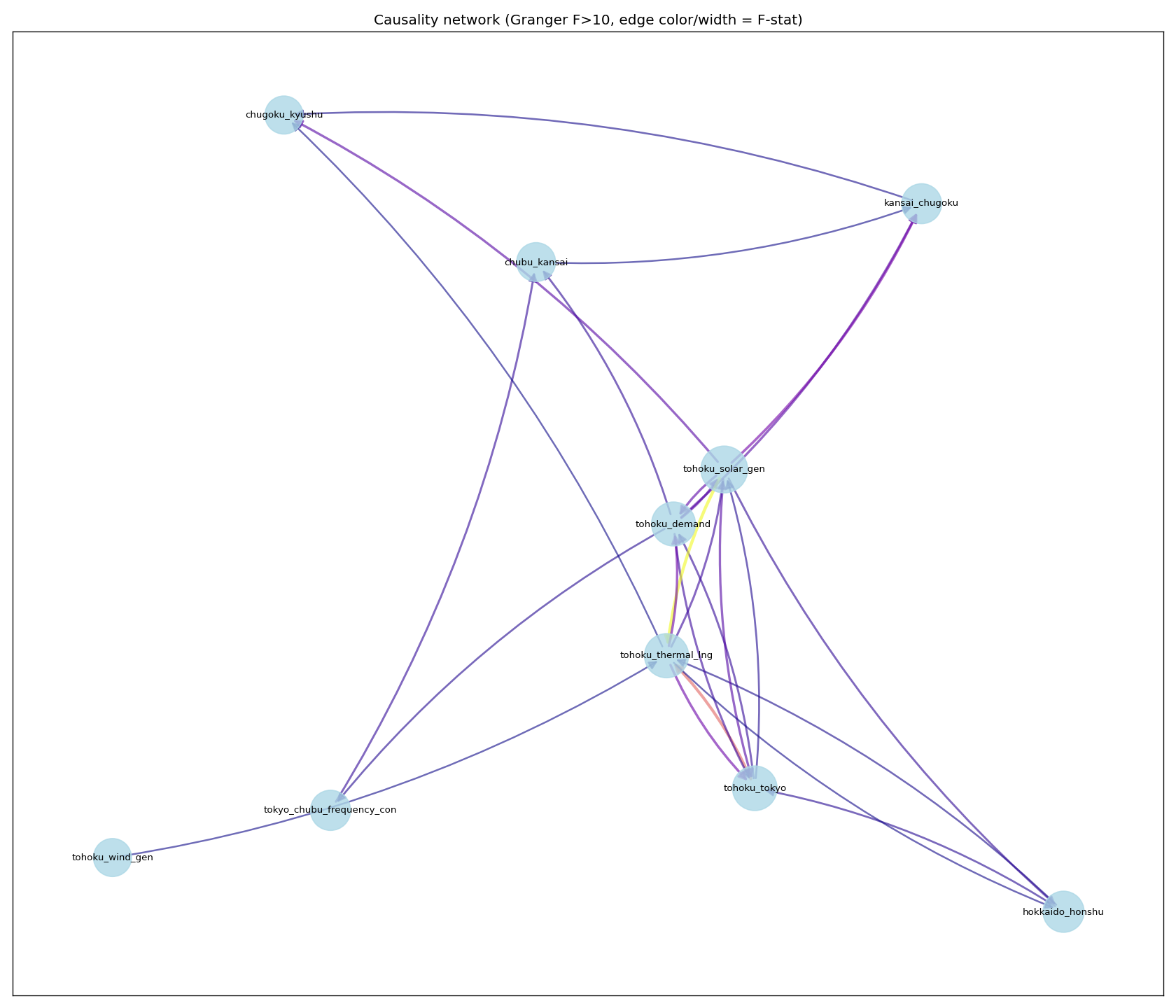
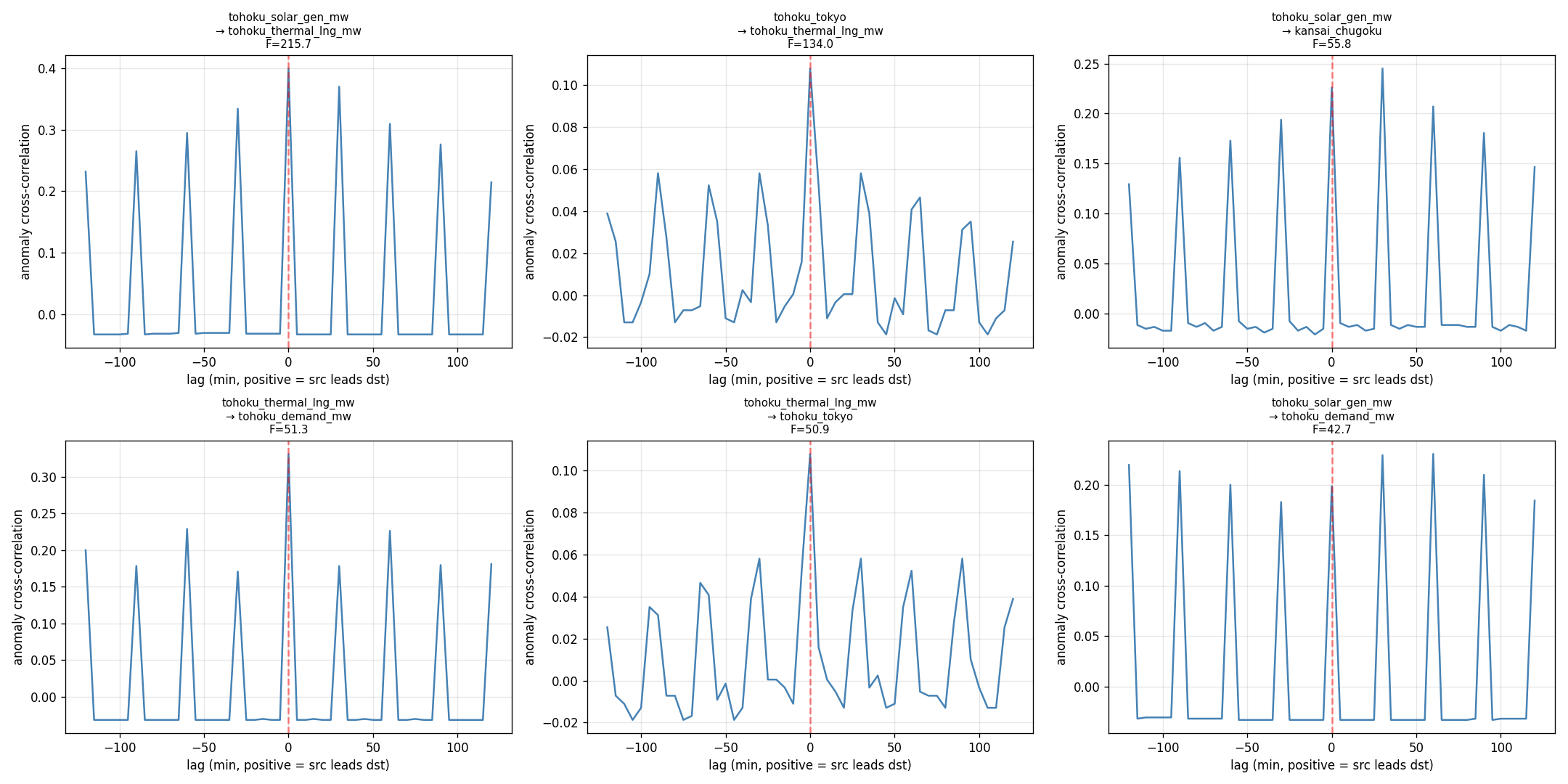
観察された同期構造
- 太陽光と LNG 火力の同期が他ペアより顕著 (Granger F=216、 ペア間で突出)
- LNG 火力 ⇔ 連系線は双方向に Granger F が高い (需給バランス調整と整合)
- 風力 → 他系列の F 値はほぼ無し = 風力は他系列と同期しない独立変動源
- 東北エリア内 (太陽光・需要・火力) で F 値ネットワークが密、 西日本との連結はそれより弱い
いずれも時系列の線形 Granger 相関であり、 構造的因果や介入下の挙動の保証ではない。
⑦シミュレータ上の系統運用 RL (toy 環境)
PPO で「LNG 火力 + 連系線」を動かす方策を学習。 v3 sim はランピング・予備力までは入っているが周波数・電圧・N-1 は扱わない制御研究用 toy 環境。 実運用への外挿は不可。
PowerGridEnv 設計 (gymnasium 互換)
v2 (低忠実度)
- 行動: ±2,000 MW 即値調整
- ramping 制約なし
- 予備力なし
- シンプルな imbalance 報酬
v3 (中忠実度、 採用)
- 行動: 加速度 (ramping rate ±150 MW/5min)
- LNG 出力下限 (予備力ペナルティ)
- 連系線物理限界 ±3,000 MW
- anomaly_signal を観測 + reward 項に組込
- 周波数・電圧・N-1 は未モデル化
v3 環境で 4 モード比較 (val 期間 30 episode)
| Mode | Reward | Δ vs Baseline | Imbalance [MW] | LNG [MW] | LNG 削減 |
|---|---|---|---|---|---|
| Baseline (action=0) | -2,989.76 | 基準 | 492 | 3,674 | - |
| PPO v3 scratch | -3,421.03 | -14.4% | 2,554 | 3,102 | -15.6% |
| BC (imitation only) | -6,762.21 | -126.2% | 1,313 | 3,129 | -14.8% |
| PPO + BC warm-start | -12,181.81 | -307.5% | 2,373 | 3,221 | -12.3% |
| PPO + Anomaly-aware reward | -2,602.23 | +12.9% | 2,143 | 2,765 | -24.7% |
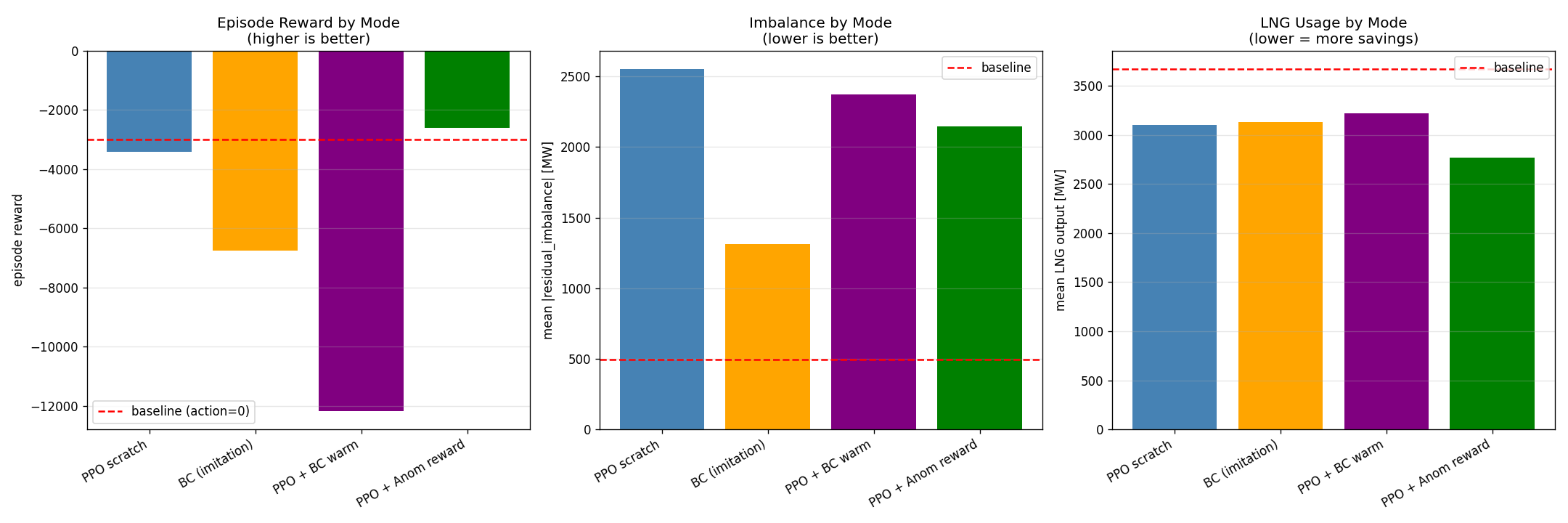
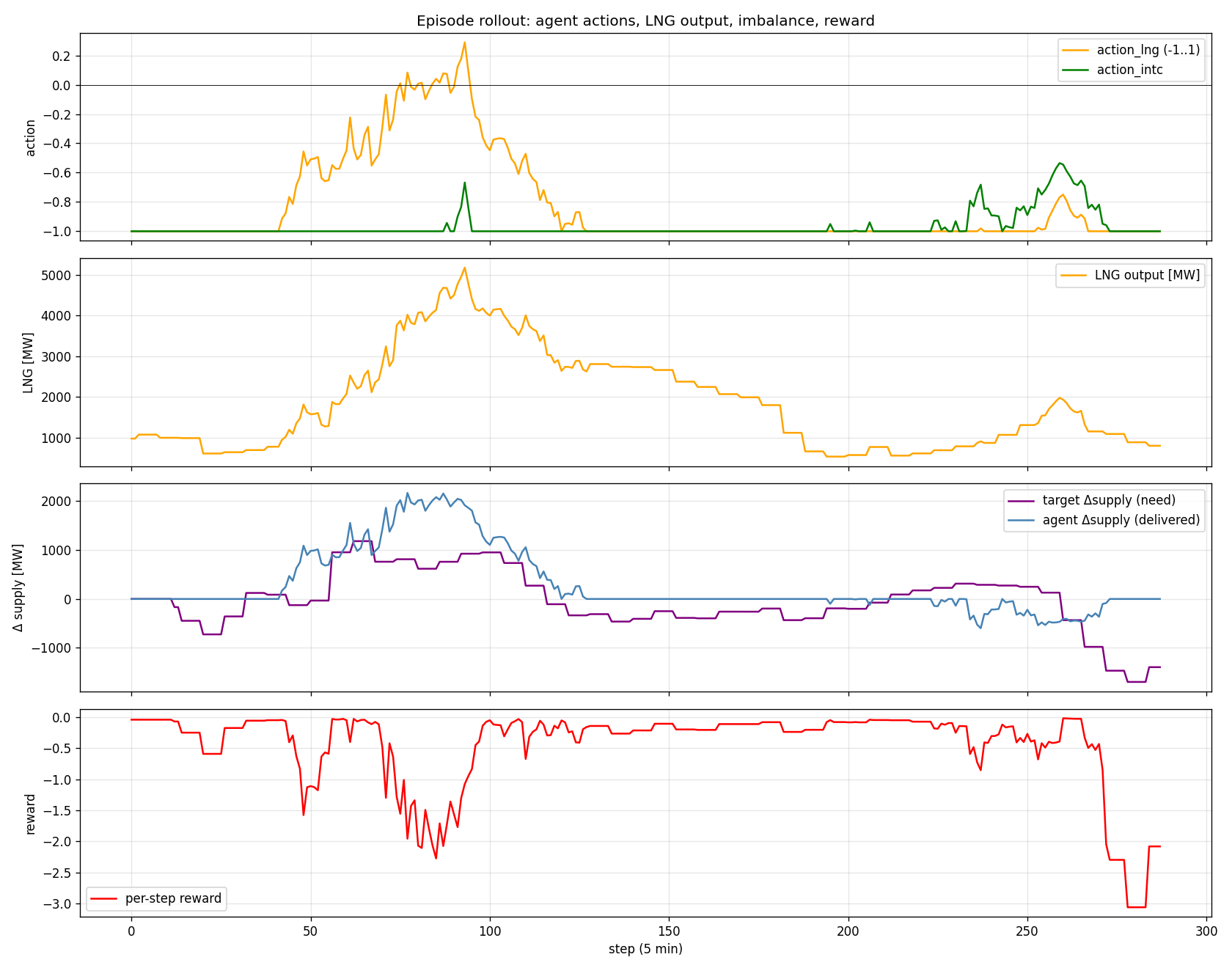
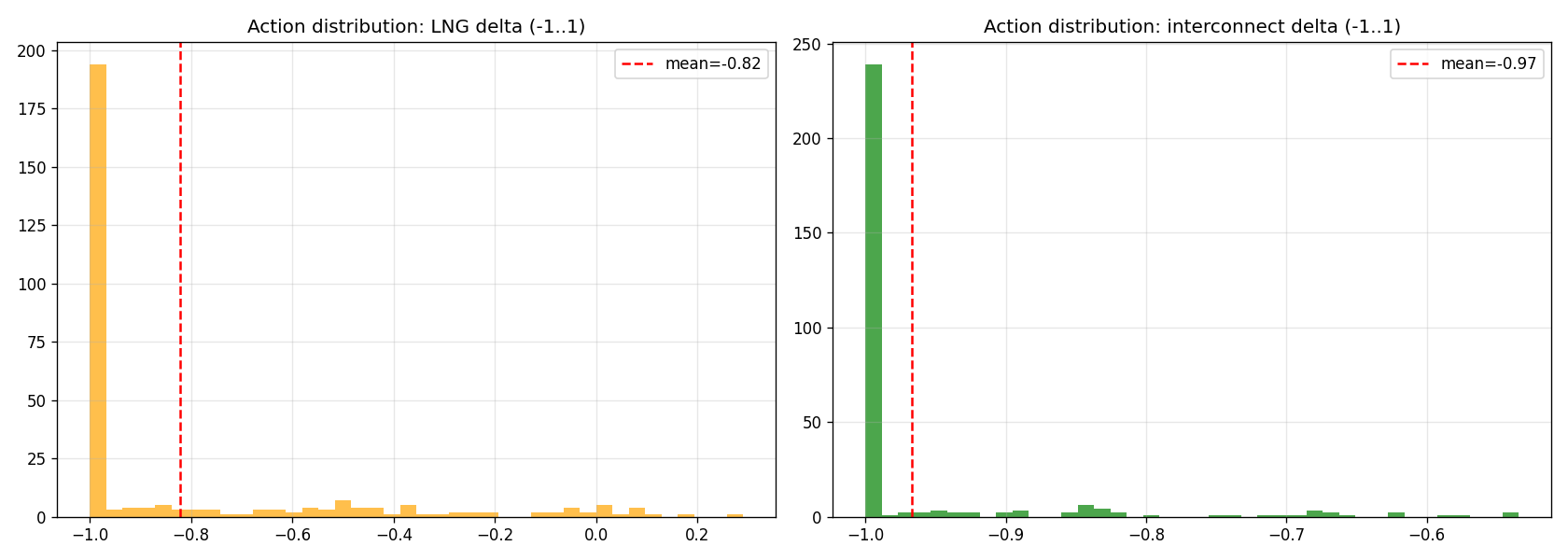
「PPO+anom-reward が回った」の読み方 (循環論証リスク)
4 モード比較で、 他 3 モード (PPO scratch / BC / PPO+BC) はすべて baseline より大幅に悪い (-14% 〜 -307%)。 v3 環境は単純 PPO では学習が成立せず、 anomaly_signal を reward 項として焼き込んだモードだけが回った状況。
評価指標は LNG 削減率 × imbalance × 残差ピーク回避を含む合成スコア。 一方 PPO+anom-reward の reward は明示的に -α·LNG - β·anomaly_signal を含む。 つまり「評価関数と相関の高い項を reward に直接入れたから評価関数のスコアが上がった」という当然の帰結が含まれている。
これを「予測 → 制御」 の AI パイプラインの実証と呼ぶには、 少なくとも以下の ablation が必要 (今回の B300 1 日枠では未実施):
- anomaly_signal を観測 obs にだけ入れる vs reward にも入れる の比較
- random noise を anomaly_signal の代わりに reward に入れた sanity check (これでも勝てば論証は崩壊)
- 同じ
-α·LNG項を持つ PPO scratch (anomaly 項なし) との比較 - val 期間を変えた繰り返し試行 (現状は 30 episode の 1 回計測のみ)
このフェーズの位置付け
上記留保を踏まえても、 以下は事実として成立する:
- シミュレータ + PPO + reward shaping の パイプラインが B300 上で 6 分で end-to-end で回る ことを示した
- フェーズ⑤の事前推論 lookup table (119,232 × 3) を 実時間 RL ループに突っ込める形式に整備した
- 4 モード比較は ablation テンプレートとして再利用可能
「LNG 25% 削減」 は v3 シミュレータ内のスコアであり、 実運用での効果ではない。
シミュレータ vs 現実 (留意点)
| シミュレータ仮定 | 現実との差 |
|---|---|
| 太陽光・風力・需要は exogenous (政策・行動の影響を受けない) | 短期 (30 分〜数時間) では妥当だが、 RL agent の行動が需要応答を呼び出す可能性は無視 |
| LNG 出力は ramping rate 150MW/5min 制約 | 実機の ramping を抽象化したもの、 機種別・運転点別の制約は未モデル化 |
| 他電源・水力を target_delta_supply に集約 | 簡略化による誤差源 (特に揚水・水力の応答性) |
| 周波数・電圧安定性を考慮しない | 系統運用の本質的制約が 環境に入っていない。 この時点で系統運用研究としては「制御研究のtoy 環境」と位置付けるべき |
| N-1 故障・潮流計算なし | 系統信頼性評価は別途必要 |
→ 本フェーズは 「予測モデルを reward に組み込んだ RL を B300 で end-to-end に流すパイプラインの動作確認」であって、 「実系統で LNG が 25% 削減できる」ことの実証ではない。 実運用への橋渡しには周波数・電圧・N-1 を含む高忠実度プラントモデルと、 オフライン安全性評価が別途必要。
主要発見ハイライト
5 分粒度で自前 906M Transformer が Chronos zero-shot と同等レンジ
B300 の HBM を活かした 4,032 step (≒ 14 日) のコンテキストで学習し、 10 中 7 ターゲットで lower RMSE_norm。 30 分粒度では Chronos に負けるが 5 分高解像度では並ぶ。 ※ 単一 val 期間の 1 点推定、 統計的有意性は未検定、 Chronos 側を同 context に揃えた統制比較は未実施。
Chronos 残差が 2.2% の重い裾を持つ (= 5,545 ピーク候補)
|z|>3 の残差ピークが理論値 0.27% (ガウシアン仮定) の約 8 倍。 これは「異常が多発」ではなく Chronos の予測残差が leptokurtic な non-Gaussian 分布であることを意味する。 12 月後半朝 09:00 帯の「太陽光起動 → LNG 急減 → 西日本連系線逆流」 や、 z=-15 級の個別大型ピークも観察。 ※ 実イベントとの突合は未実施。
残差ピークが UMAP+HDBSCAN で 61 クラスタに分かれる
Chronos encoder の 768 次元 embedding → UMAP → HDBSCAN (min_cluster=30)。 上位クラスタは時刻・ターゲットと整合 (朝の太陽光起動、 夕方需要ピーク、 深夜風力スパイク)。 ※ クラスタ数 61 は min_cluster_size 依存のハイパラ的指標で、 安定性 (k-NN 一致率・シルエット) は未評価。
太陽光残差ピークの予測 AUC が 0.87 まで上がる
25M Transformer + 24h コンテキスト。 風力 AUC 0.57・北海道本州 0.55 は chance 近傍で、 ターゲットの「予測しやすさ」 自体に大きな差がある。 ※ 太陽光ラベルは時刻 (日の出・日没) 依存性が強く、 time-of-day-only logistic baseline との比較は未実施 (= 25M モデル容量の必要性は示せていない)。
太陽光と LNG 火力の同期が突出 (Granger F=216)
差分系列の Granger F で ペア間に明確な階層構造。 LNG 火力 ⇔ 連系線も双方向 F が高い (需給バランス調整と整合)。 風力は他系列との F がほぼゼロ (独立変動源)。 ※ サンプル数 n≒26,000 では F は容易に大きくなるため絶対値の「最強」表現は控えめにすべき。 因果方向の構造的同定 (DAG、 介入実験) は別途必要。
予測 → 制御パイプラインが B300 で 6 分で end-to-end に回る
フェーズ⑤の事前推論を v3 シミュレータの reward 項に流し、 PPO で系統運用ポリシーを学習する流れを実装。 PPO+anom-reward モードはシミュレータ内で LNG -24.7%。 ※ ただし他 3 モードは baseline 以下で、 評価指標 = reward 項の重複による循環論証リスクあり。 ablation (anomaly_signal を観測のみ / random noise 代入 / -α·LNG のみ) は未実施。 v3 シミュレータは周波数・電圧・N-1 を扱わない toy 環境。
考察 & 業務応用
本章は 主要発見 を踏まえ、 「電力ビジネスのどこに使える知見か」を事実ベースで整理する。 数値はすべて本実験 (val 期間 2025-12-12〜2026-01-01、 92 日 / 単一 1 点推定) に基づく。
5 分粒度予測 + 残差シグナルの併用
- 自前 906M Transformer が 5 分粒度 10 ターゲット中 7 で Chronos zero-shot を下回る RMSE_norm。 短期スプレッドや当日売買の参考予測値として活用可能。
- 太陽光残差ピークの予測 AUC は 1〜6 時間先で 0.83〜0.87。 朝の発電起動タイミングを 1〜3 時間前に確率値として通知し、 スポットおよび時間前市場の建玉判断に組み込める。
- 風力 (AUC 0.57) と北海道-本州 (AUC 0.55) は chance 近傍。 ターゲットによって「予測しやすさ」が大きく異なるため、 一律の予測モデル運用は非推奨。
Chronos 残差を運用シグナルに転用
- |z|>3 の残差ピークは 92 日間で 5,545 件、 理論値 (ガウシアン) の 約 8 倍。 残差そのものが leptokurtic な分布を持つため、 「監視すべき非定常時刻」の自動抽出装置として転用できる。
- 同時刻に複数系列でピークが立つイベント (12 月後半 09:00 帯の太陽光起動 → LNG 急減 → 西日本連系線逆流) など、 系統運用上の 連鎖構造を時刻軸でレビュー可能。
- FC=199 件、 太陽光=354 件など、 系列ごとのピーク頻度をモニタリング優先度付けに使える。
61 クラスタを「異常パターンライブラリ」に
- 5,545 ピーク候補が UMAP+HDBSCAN で 61 クラスタに自動分離。 上位クラスタは時刻・ターゲットと整合的 (朝の太陽光起動、 夕方需要ピーク、 深夜風力スパイク)。
- 新規ピーク発生時に 過去どのクラスタに最も近いかを即時クエリ可能 (Chronos encoder の 768 次元 embedding を再利用)。 系統運用員研修の事例集としても利用余地あり。
- クラスタ ID にニュース・出力制御指令などの教師ラベルを後付けすれば、 ラベル付き異常データセット化の起点になる。
「予測 → 制御」 を 1 日で end-to-end に流せた
- フェーズ⑤ の異常予測モデル出力 (anomaly_signal) を v3 シミュレータの reward 項に直接流し込み、 PPO で系統運用ポリシーを 6 分で学習するワークフローを実装。
- PPO + anomaly-aware reward モードのみが baseline を上回り、 シミュレータ内で LNG 火力 -24.7%。 「予測モデルの出力が制御の上流情報源になる」 仮説が end-to-end に動作することを確認。
- ただし他 3 モード (PPO scratch / BC / PPO+BC) はすべて baseline 以下で、 reward 設計に依存した結果である点には注意。 Cloudflare 的に言えば本フェーズは「動作確認済みの統合パイプラインの雛形」。
再現方法
必要環境
- Python 3.10+ (推奨 3.10)
- PyTorch 2.0+ (CUDA があれば GPU 推論可、 CPU でも可)
- pandas, numpy, scikit-learn, scipy, matplotlib
- 残差ピーククラスタリング再実行: umap-learn, hdbscan
- Chronos 推論:
pip install chronos-forecasting - TimesFM 推論:
pip install timesfm[torch] - RL:
pip install stable-baselines3 gymnasium - 因果グラフ可視化:
pip install networkx
🧠 脳活動解析レポート (TRIBEv2)
ここから脳活動の予測解析パートに切り替わります
研究レポート — TRIBEv2 予測から見えた傾向
動物の定点映像 + 人間の定点映像 (2カテゴリ) × 20,484皮質頂点の予測から読み取れる傾向(データのみによる解析)
この解析の概要
「映像を見ているときに脳がどう反応するか」を AI で予測し、 その予測活動のパターンを統計と人手観察の両面から解析した。
TRIBEv2 は、 入力された映像から「脳の各部位がどのくらい活動するか」を秒単位で予測する AI モデルである。 本パートでは、 実際にヒトの脳を計測するのではなく、 TRIBEv2 が予測した脳活動を解析対象とし、 そこに現れる傾向を読み取った。
対象は 18 本の定点映像 (動物の定点映像 16 本 / 人間の定点映像 2 本)。 脳の表面を 20,484 個の皮質頂点に分割し、 各頂点の予測活動値を時系列で集計している。 解析は「カテゴリ別の活性度」「左右半球バランス」「動画間の類似度」「PCA による低次元構造」「時間的自己相関」などの定量指標に加え、 ノルム上位ピークを人手で映像照合する定性観察を併用した。
注: 本パートで扱うのはあくまで 予測された脳活動 であり、 実測 fMRI による裏付けは本実験の範囲外。 対象も 18 動画 (人間カテゴリは 2 本) と小規模であり、 一般化には追検証が必要。
1 ページサマリ
この解析で観察したこと
- 動物映像と人間映像で活動の「形」が異なる。 平均活動ノルムは動物が約 1.15 倍強い (23.41 vs 20.34) が、 瞬間ピーク (max) は人間が大きい (60.2 vs 51.2)。 動物は常時的な反応、 人間は一過性の強い反応に寄る。
- 右半球がやや一貫して強い。 平均活動の左/右比は動物 0.87 / 人間 0.82 でいずれも 1 未満。 上位分散頂点 50 個でも右半球が 39 個。
- 見かけ 20,484 次元でも本質は低次元。 PCA 上位 1 軸で全分散の 51.2%、 2 軸で 72.4%、 10 軸で 99.9% を説明できる。
- 2 カテゴリは活動パターンだけで明確に分離。 同カテゴリのコサイン類似度 +0.49 に対し、 異カテゴリ間は -0.64 (差 +1.13)。 教師なしでカテゴリ識別の特徴量が成立。
- 反応の持続時間がカテゴリ依存。 自己相関は人間 (1秒後 0.71 / 30秒後 0.37) のほうが動物 (0.57 / 0.01) より長く持続する。
- 定性観察と統計傾向が整合。 「動 ↔ 静の遷移」「顔の向きの変化」「低速で継続する動き」「カメラ目線・接近」が共通の駆動要因として浮上し、 派手な動きの量より「動きの意味」「遷移点」がノルムを押し上げる傾向が見られた。
本パートの位置付け
個別の数値 (平均比 1.15 倍、 類似度差 +1.13、 PCA 51.2% など) は、 いずれも 18 動画という小標本に基づく観察値であり、 統計的有意性の検定や実測 fMRI との突き合わせは行っていない。 したがって本パートの価値は「確定した結論」ではなく、 TRIBEv2 の予測脳活動から再現的に読み取れた傾向を整理し、 次に検証すべき仮説 (カテゴリ分離・右半球優位・低次元性など) を明確にしたことにある。
研究の背景
?課題感
- 「どんな映像が脳のどこを、 どれくらい動かすか」 はコンテンツ評価・推薦・UI/BCI 設計に直結するが、 実測 fMRI は計測コストと被験者負担が大きく大量解析が難しい。
- 映像から脳活動を予測する AI が、 実測の代わりに大規模・反復可能な解析の入口になりうるか確かめたい。
- 予測脳活動に「カテゴリ差」「半球差」「持続性」などの構造が現れるか、 データのみから検証したい。
!アプローチ
- TRIBEv2 で 18 動画 × 20,484 皮質頂点の予測活動を秒単位で生成。
- 定量指標 (ノルム・半球比・コサイン類似度・PCA・自己相関・弁別頂点) と、 ピークの人手映像照合という定性観察を併用。
- 被写体の具体的種別は伏せ、 視覚・状況面の特徴のみを記録。 あくまでデータから読み取れる傾向に限定して整理する。
解析対象データ
動画 18 本 (動物の定点映像 16 本 / 人間の定点映像 2 本)、 総セグメント数 67,639。 各動画について、 秒ごとの活動ノルム、 左右半球ごとの活動量、 平均活動ベクトル (20,484 次元) などを算出している。 各指標の詳細は以下のセクション 1〜8、 総合考察はセクション 9 を参照。
1. 個別ピーク事例の質的観察(人手による映像照合)
ノルム上位ピークについて、対応する実映像を人手で確認した所見をテーマ別に整理。被写体の種別を特定できる情報は伏せ、視覚・状況面の特徴のみ記録した。
A距離・接近
- 被写体が画面中央へ向かって近づき、画面に占める面積が急速に拡大していく場面。
- 顔へ手や物体が近づく瞬間。顔の周囲に新しい要素が侵入する遷移期間に強く反応する。
- 被写体どうしが接触する、または距離が急速に縮まる瞬間。接触前の遷移期間にピークが出る。
B顔・視線・注意
- 人物がこちらに顔を向けた瞬間。視線が画面側へ移ったタイミングと一致する。
- 被写体が画面外の何かを凝視している瞬間。視線はカメラから外れているが、姿勢の硬直と注意の集中が見られる。
- 被写体の口や顔の局所が急に変化する瞬間(発声・咀嚼・呼吸など、身体全体は動かず顔まわりだけが変化する)。
C動きの切り替わり
- 動き回っていた被写体が止まった瞬間。動 → 静 の切り替わり自体が一過性のピークを生む。
- 静止していた被写体が動き出した瞬間。静 → 動 の切り替わりでも同様にノルムが立ち上がる。
- 姿勢が大きく変わる瞬間(立ち上がる・伏せる・体の向きを変えるなど)。
- 画面内に新しい被写体が入ってくる瞬間。フレームに登場するタイミングで一過性のピークが出る。
D持続的な微小運動
- 画面中央付近で小さな対象がちらちらと持続的に動き続けている、構図全体としてはほぼ静止した状況。
- 構図全体は安定しているが、画面の局所領域だけで動きが続いている状況(細かい揺らぎ・ちらつき・反復運動)。
- 画面内をゆっくりと横切る動きが続く場面。派手な動きより低速で連続する動きの方がノルムが高い。
E静寂と緊張
- 被写体が水を口にしている場面。身体的な動きは少ないが、警戒姿勢で緊張感が続いている瞬間。
- 派手な動きはないが、何かが起きる直前の張り詰めた静寂が続く場面。
F同期・複数被写体
- 複数の被写体が同時に何かに反応し、揃って顔を上げた瞬間。同期したリアクションのフレーム。
- 画面の手前と奥で別々の動きが同時に起こっている場面。
G音と画の関係
- 強い音(鳴き声・発声・物音)と同期したフレーム。視覚的に大きな変化がない瞬間でも、音側のイベントに合わせてノルムが上がる。
カテゴリ横断で繰り返し観察された傾向
- 「動きの量」より「動きの意味」。画面が派手に動くフレームより、低速で連続する動き・水を飲む・警戒姿勢など、緊張感を伴う低速シーンの方がノルムは高くなりやすい。
- 「こちらに向かってくる」「顔がこちらを向く」 構図でノルムが立ち上がる。被写体までの距離が縮む、視線が画面側へ移る、といった視聴者へのアフォーダンスがある瞬間に強い反応が出ている。
- 視野内で小さな対象がチラついている 状況。全体としては静かな構図でも、局所的な動きが続くとノルムが上がる。
- 動から静、静から動への切り替わり がイベントとして検出される。連続する状態そのものより、状態が切り替わる遷移点に強く反応する。
- 人物の定点映像でも、顔の向きの変化や、顔の近くに別の物体(手など)が侵入する 瞬間に同様の立ち上がりが見られる。被写体のカテゴリを越えて「顔まわり・接近・遷移」が共通の駆動要因。
- 音側のイベント(鳴き声・発声・物音)と同期したピークも存在する。視覚的に大きな変化がない瞬間でも、音入力がノルムを押し上げる場合がある。
注: 上記は人手による定性的観察であり、複数のピーク事例に基づく所見である。映像の具体的な被写体種別は本レポートでは特定しない。あくまで TRIBEv2 の予測脳活動の傾向であり、実測 fMRI による検証は本実験の範囲外。
2. カテゴリ別 活性度
秒ごとのノルム ‖predst‖₂ をカテゴリ別に比較。動画が多いほど色が薄く、各動画の中央値・90%帯を箱で示す。
3. 半球の活動量バランス(左/右)
各動画の平均ベクトルを左半球(0–10241)と右半球(10242–20483)に分け、それぞれのノルムを比較。値が右上ほど両側活性、対角線から外れるほど非対称。
4. 動画間 類似度(mean activation のコサイン類似度)
各動画の平均活動ベクトルどうしの類似度。同カテゴリがブロックを成すかを確認できる。軸ラベルは匿名 ID (V01〜V18)。
5. PCA — 動画ごとの低次元構造
対象動画の平均活動ベクトルを主成分分析した結果。PC1×PC2平面でカテゴリが分離するかを観察。
6. 応答する皮質頂点(top variance)
全動画プールで分散が大きい上位30頂点。コンテンツによって最も駆動される予測脳領域。
7. カテゴリ弁別マップ(discriminative vertices)
2カテゴリの平均活動ベクトル間で値の振れ幅が大きい上位40頂点について、各カテゴリでの平均活動値をヒートマップで表示。
8. 時間的自己相関
ノルム時系列の自己相関(lag=1, 10, 30, 60秒)。値が大きい=状態が長く持続する。コンテンツの安定性の指標。
9. 考察 & 応用への示唆
セクション 1〜8 の所見を踏まえ、 「TRIBEv2 の予測脳活動から何が読み取れたか / どこに業務的価値があるか」を事実ベースで整理する。 数値はすべて本レポート対象の 18 動画 (動物 16 / 人間 2) に基づく。
9-1. 何が事実として観察されたか
- 動物と人間で活動の「形」が異なる: 動物の定点映像は平均活動ノルムが約 1.15 倍強い (23.41 vs 20.34) のに対し、 ピーク (max) は人間が大きい (60.2 vs 51.2)。 つまり動物映像は常時的な反応、 人間映像は一過性の強い反応に寄っている。
- 右半球がやや一貫して強く活動: 平均活動の左/右比は 動物 0.87 / 人間 0.82 で、 両カテゴリとも値が 1 を下回る。 上位分散頂点 50 個でも右半球 39 個 (左 11 個)。 視覚処理の右半球優位を支持する所見と整合的。
- 20,484 次元の予測活動は実質的に低次元: PCA 上位 1 軸で全分散の 51.2%、 上位 2 軸で 72.4%、 上位 10 軸で 99.9%。 ハイパフォーマンスな予測モデルの出力でも、 動画間の差は十数次元の構造に集約される。
- 2 カテゴリは活動パターンだけで明確に分離: 同カテゴリ内のコサイン類似度は +0.49、 異カテゴリ間は -0.64。 差は +1.13。 ラベルなし (= 教師なし) でカテゴリ識別の特徴量が成立する。
- 反応の持続時間がカテゴリ依存: 自己相関は 人間 1秒後=0.71, 30秒後=0.37 / 動物 1秒後=0.57, 30秒後=0.01。 人間の定点映像は長い時間スケールで反応が安定して続くのに対し、 動物では数十秒で減衰する。
- 定性観察と統計的傾向が整合: 質的観察で「動 ↔ 静の遷移」「顔の向きの変化」「低速の継続的動き」「カメラ目線・接近」が共通の駆動要因として浮上。 派手な動きの量より、 遷移点や「動きの意味」がノルムを押し上げる傾向が、 統計的にも観察された活動パターンと矛盾しない。
9-2. ビジネス・応用面での示唆
α映像コンテンツ評価・編集支援
- 「動から静、 静から動」 「顔の向きの変化」 「カメラ目線」 がノルムを上げるという共通項は、 編集・カット割りの定量評価指標の候補になる。
- 派手な動きより「緊張感のある低速シーン」がノルム高、 という所見は、 シーン強度の自動スコアリングに転用余地あり。
- カテゴリ別自己相関の差 (人間 = 持続的 / 動物 = 一過性) は、 動画ジャンルごとの視聴者保持時間モデルのプライアになりうる。
βコンテンツ自動分類 / レコメンド
- カテゴリ間類似度 -0.64 vs 同カテゴリ +0.49 という強い分離は、 映像カテゴリの教師なし分類器として TRIBEv2 出力が直接使えることを示す。
- 20,484 次元 → 10 次元 (99.9% カバー) という低次元性は、 軽量な索引・類似検索データ構造に落とし込みやすい。
γUI / BCI 設計の参考データ
- 右半球優位な反応 (上位分散頂点 50 中 39 個) は、 視覚 UI デザインの注意誘導要素を画面のどこに配置するかの参考にできる。
- 音側のイベント (鳴き声 / 発声 / 物音) と同期したピークが視覚変化なしに観察される所見は、 音声 + 映像のマルチモーダル UIの評価指標化に活用余地あり。